Support Vector Classifier (SVC) is a non-parametric classification algorithm that is based on geometric representation of linearly seperable data. In this article we are going to go through the development of the SVC algorithm step by step. Firstly, Because of the geometric background of SVC, let’s start with data that has only 2 features, therefore it can be rerresented in 2D, which makes visualiztion much easier and thereafter all the concepts in 2D will generalize well for higher dimensions.
The shape of data
Let’s say we have tabular data in the following form.
Where each row in the table consists of two components, the first component is a point Xi in the space R2 such that Xi=(xi1,xi2) and the second component is the group to which Xi belongs yi∈{−1,1}.
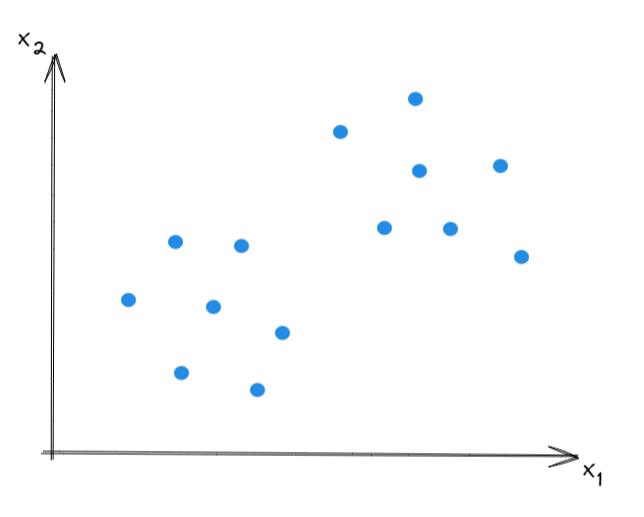
The data when ploted in 2D should be linearly seperable, and it would look something like in the following plot.
Geometrical Data classification
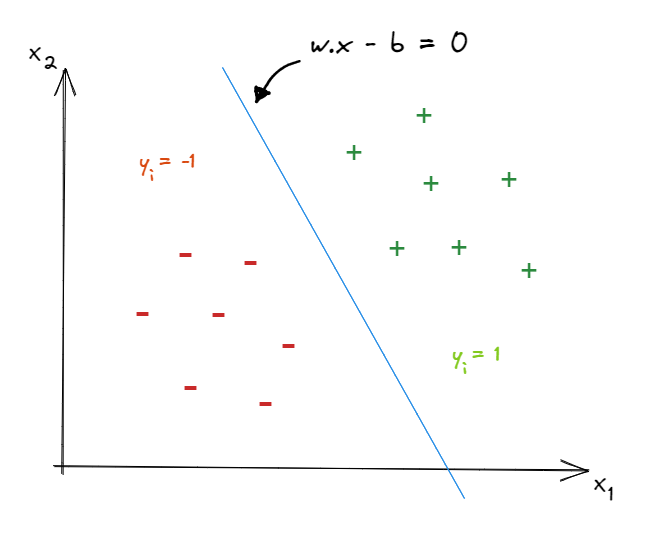
The goal of SVC is to figure out a line that separate the two groups of data in a best way. We will elaborate more on how this best way works in the upcoming section.
Line equation
It is important to note that the line equation used to describe the seperation line that we are after is not the commonly used slope-intercept form (y=mx+c). The reason is, the slope-intercept form fails to describe the vertical line, which might be a candidate for a seperation line in SVC. Let’s take an example. L1 is a vertical line at x=a, now if we took two points on L1, p0=(a,y1) and p1=(a,y2), then:
m=a−ay2−y1=0y2−y1=∞
Therefore, we use the general form of line-equation instead, Ax+By+C=0 that can describe a verticle line at x=a by setting A=1, B=0 and C=a. The general form has another helpful characteristic, it tell if a point fall above or under a line. e.g. if L is a line that has the following general form a1x+b1y=c1 and p=(x1,y1) is a point, then by plugging p in L we get a value v=a1x1+b1y1−c1, v>0 means the point p is above the line L, v<0 means p is below L, finally, v=0 means p is on L.
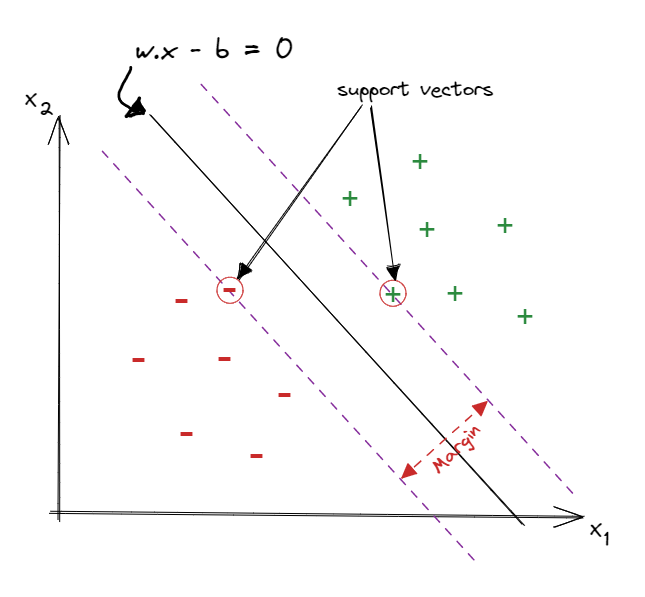
Now let’s redraw the previous figure, adding a line between the two clusters and label the points in the cluster above the line as (+) and the points in the cluster below the line as (-). The line could be expressed in a vector notation as wx−b=0.
The methodology to choose the best separation line
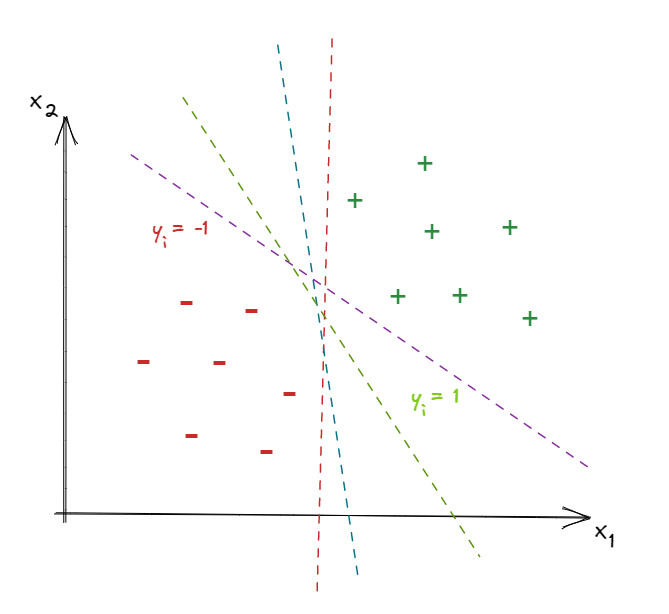
How to determine the w and b that result in the best separation line, among many line candidates?
The approach of SVC to choose the best seperation line is to find two parallel lines that each of them goes through at least one edge point of each group, and the best pair of lines is the one that has the largest distance between them “This distance is called the margin”, then the seperation line is situated in the middle between these two parallel lines and parallel to them. This approach is called the widest street approach and the edge points of each clusters that the parallel lines go through are called support vectors.
Margin width formulation
Now we want to formulate the margin width so we can use the assumed formula for maximizing the distance between the two data groups. To get to this point, we go through the following steps.
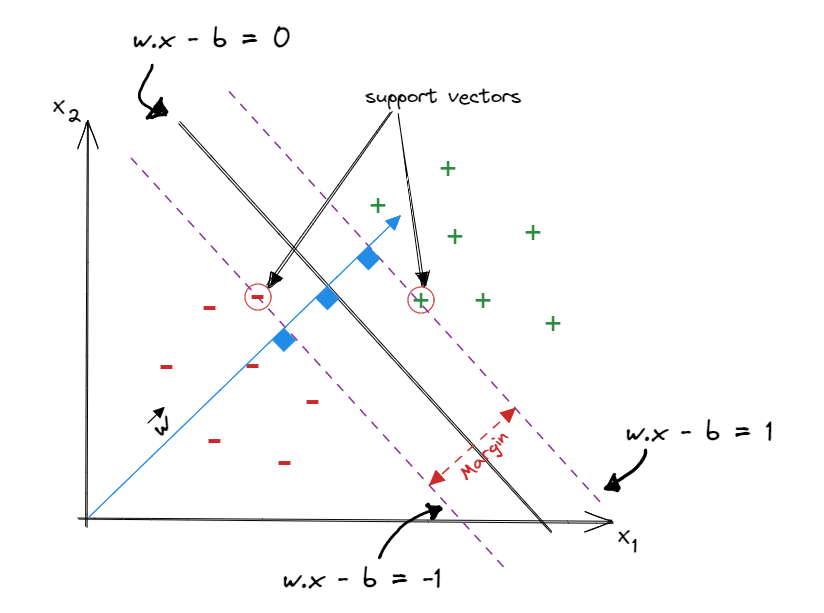
1- The line "wx−b=0" could be written as "wx=0" by including 1 in the vector x and −b in the vector w.
wx−b=[w1w2−b]x1x21=wx=0
wx=0⇒w is perpendicular to x
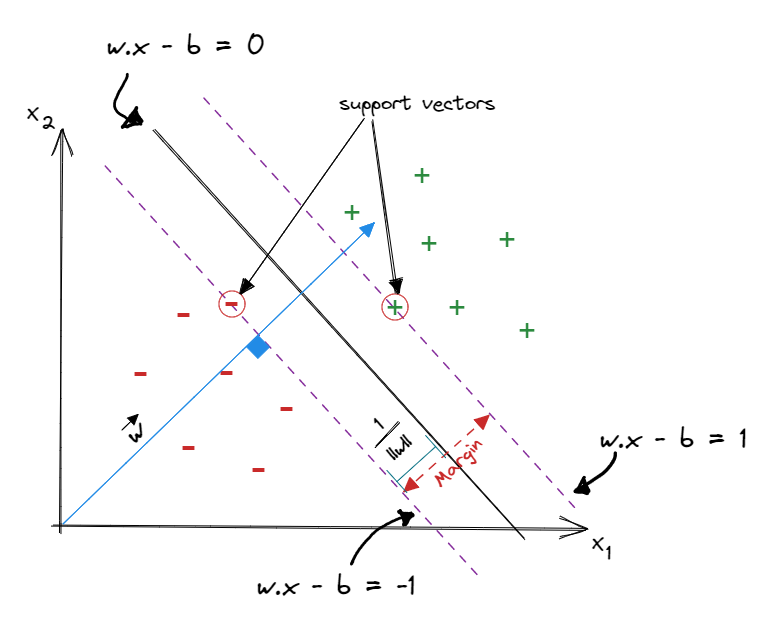
Now we can calculate the distance from the line wx−b=0 to the line wx−b=1 or the line wx−b=−1 as multiples of the unit vector of w, starting from a point x∗ on the line wx−b=0. Let’s calculate the distance from the line wx−b=0 to the line wx−b=1 and denote this distance as k. Therefore the corresponding point x+ on the line wx−b=1 is x+=x∗+k∣∣w∣∣w,margin=2k
∵x+ is on wx−b=1
⇒w(x∗+k∣∣w∣∣w)−b=1
wx∗+k∣∣w∣∣ww−b=1
wx∗−b+k∣∣w∣∣ww=1
∵x∗ is on the line wx−b=0→wx∗−b=0
⇒wx∗−b+k∣∣w∣∣ww=k∣∣w∣∣ww=1
∴k=ww∣∣w∣∣=∣∣w∣∣2∣∣w∣∣=∣∣w∣∣1
k=∣∣w∣∣1,margin=2k=∣∣w∣∣2
Margin width maximization
Now we have a measure for the margin and we have to maximize it as the SVC approach instructs.
maximize(∣∣w∣∣2)s.t
wx−b≥1ifyi=1,wx−b≤−1ifyi=−1
we can merge the two constraints into one as follows wx−b≥1ifyi=1,wx−b≤−1ifyi=−1 ⇒yi(wxi−b)≥1,yi∈{1,−1}
⇒maximize(∣∣w∣∣2),s.tyi(wxi−b)≥1
maximize(∣∣w∣∣2)≡minimize(∣∣w∣∣)
minimize(∣∣w∣∣)≡minimize(21∣∣w∣∣2)
we choose to minimize 21∣∣w∣∣2 for mathematical convenience.
The Lagrangian multipliers
The Lagrangian multipliers method is used to include constraints along with the minimization problem into a Cost function.
The general form of the Lagrangian multipliers method is, we have a minimization problem minimize(f(w)) s.t g(w)≤ 0, h(w) = 0, Then:
we don’t have equality constraint →∑i=1lβihi(w)=0
⇒J=21∣∣w∣∣2+∑i=1nαi{1−yi(wxi−b)}s.tαi≥0
=21∣∣w∣∣2−∑i=1nαi{yi(wxi−b)−1}s.tαi≥0
from a Lemma
maxαJ(w,b,α)={f(w),∞,statisfies all the constraintsotherwise⇒maxαJ(w,b,α)={21∣∣w∣∣2,∞,1−yi(wxi−b)≤0∀i=1,...,n,otherwise
⇒ The primal problem J can be expressed as minimizew,b{maximizeα{J(w,b,α)}}
The dual problem formulation
Let p∗ be solution for minw,bmaxαJ(w,b,α)
, there is an option to minimize J first, then maximize it, maxαminw,bJ(w,b,α), this order flip turn the primal lagrangian problem into what is called the dual problem.
let d∗ be a solution for maxαminw,bJ(w,b,α)
Finding the solution d∗ is based on two theorms, the weak duality and the strong duality theorms.
The weak duality theorm implies that d∗≤p∗.
The strong duality theorm implies that iff there exists a saddle point of J(w,b,α)⇔d∗=P∗ and this saddle point satisfies the Karush Kuhn Tucker KKT condition which consists of the following terms
∂wi∂J(w,b,α)=0,∀i=1,2,...,k
αigi(w)=0,∀i=1,2,...,n
αi≥0,∀i=1,2,...,n
∂w∂J=w−∑i=1nαiyixi=0,⇒w=∑i=1nαiyixi
∂b∂J=∑i=1nαiyi=0
Let’s now expand the function J and substitute the terms we got from the derivatives above.