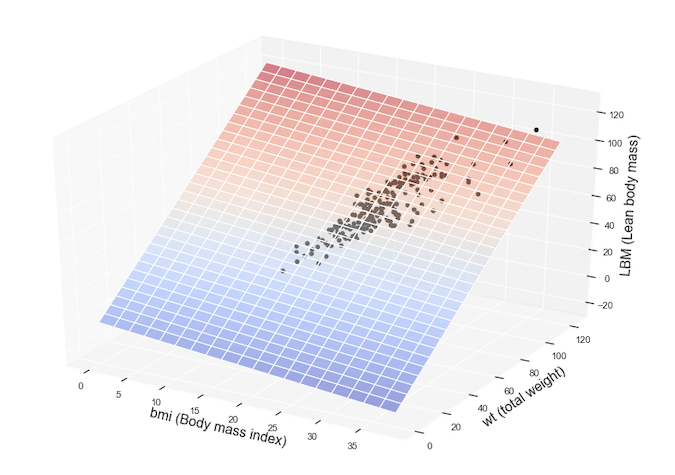
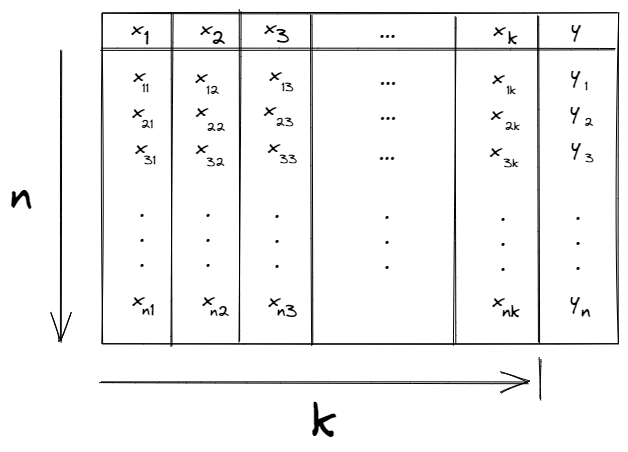
We have a tabular data that consists of 𝑛 observations, each observation represents a row in the table of data. Column-wise, the data consists of 𝑘+1 columns. 𝑘 of them are independent variables “features” x1, x2, …, xk and the last one is a “response” variable 𝑦 that its values are continous. The following figure, shows an example of how the data looks.
The goal is to use the data at hand to build a model that approximate the relationship between the dependent variable y and the set of the independent variables X={x1,x2,x3,...,xk}.
Multiple linear regression as an extention of the simple Linear regression assumes a linear relationship between the dependent variable y and the set of the independent variables X and in light of this assumption, y could be written as a linear combination of xi‘s, where i=1,2,3,...,k.
ε is called the irreducable error, because no matter how close the model we build to the true relationship, still there will be a small margin of error.
y=XB+E
A fundamental difference between the single version and the multiple version of the linear regression models is, simple linear regression assumes true linearity between y and x, modeling a relationship between one independent variable and one dependent variable as a real line y=mx+c.
On the other hand, the linearity in multiple linear regression is only required for the coeffcients βi‘s, i=1,2,3,...,k and the relationship between y and xi‘s in the set X could be non-linear. The following examples show valid and invalid variants of multiple linear regression models.
y=β0+β1x1+β2x2+β3x3+β4x12 ✅
y=β0+β1x1+β2x2+β3x3+β4x2x3 ✅
y=β0+β12x1+β2x2+β3x3+β4x4 ❌
y=β0+β1x1+β2x2+β1β2x3+β4x3 ❌
Matrix Notation
The erriducable error ε can not be estimated. Therefore our approximated model will ignore it and we will infer only the values of βi‘s. Our model is going to be in the following form y^=β0+β1x1+β2x2+β3x3+...+βkxk
Let’s say we have already calculated the βi‘s , we can then calculate yi^ for each observation in our data. We can write this approximation in a matrix notation as follows.
We want our approximated model to be as close as possible to the true relationship that generated the data. Therefore we want to see that the difference between the observed value of the dependent variable and its approximated value, goes to zero. y−y^→0.
y−y^=y1−y1^y2−y2^...yn−yn^→00...0
In other form, the overall ∑i=1n(yi−yi^)2→0
Since y^=XB^,
we can express ∑i=1n(yi−yi^)2 as ↴
(yi−yi^)2=(y−y^)T(y−y^)
(y−y^)T(y−y^)=(y−XB^)T(y−XB^)
=(yT−(XB^)T)(y−XB^)
=(yT−B^TXT)(y−XB^)
=yTy−yTXB^−B^TXTy+B^TXTXB^
∂B^∂((y−XB^)T(y−XB^))=0
⇒∂B^∂(yTy−yTXB^−B^TXTy+B^TXTXB^)=0
⇒∂B^∂yTy−∂B^∂yTXB^−∂B^∂B^TXTy+∂B^∂B^TXTXB^=0
if we have a matrix Am×m and a vector xm×1, then: